카프카 프로듀서 주요 옵션 (https://kafka.apache.org/documentation/#producerconfigs)
| 옵션 | 설명 |
| bootstrap.servers | 카프카 클러스터는 클러스터 마스터라는 개념이 없기 때문에 클러스터 내 모든 서버가 클라이언트의 요청을 받을 수 있다. 해당 옵션은 카프카 클러스터에 처음 연결을 하기 위한 호스트와 포트 정보로 구성된 리스트 정보를 나타낸다. 정의된 포맷은 "호스트 이름:포트, 호스트 이름:포트, 호스트 이름:포트"이다. 전체 카프카 리스트가 아닌 호스트 하나만 입력해 사용할 수 있지만, 이 방법을 추천하지는 않는다. 카프카 클러스터는 살아있는 상태이지만 해당 호스트만 장애가 발생하는 경우 접속이 불가하기 때문에, 리스트 전체를 입력하는 것을 권장한다. 만약 주어진 리스트의 서버 중 하나에서 장애가 발생할 경우 클라이언트는 자동으로 다른 서버로 재접속을 시도하기 때문에 사용자 프로그램에서는 문제없이 사용할 수 있게 된다. |
| acks | 프로듀서가 카프카 토픽의 리더에게 메시지를 보낸 후 요청을 완료하기 전 ack의 수이다. 해당 오셥의 수가 작으면 성능이 좋지만, 메시지 손실 가능성이 있고, 반대로 수가 크면 성능이 좋지 않지만 메시지 손실 가능성도 줄어들거나 없어진다. > acks=0 : 만약 0으로 설정하는 경우 프로듀서는 서버로부터 어떠한 ack도 기다리지 않는다. 이경우 서버가 데이터를 받았는지 보장하지 않고, 클라이언트는 전송 실패에 대한 결과를 알지 못하기 때문에 재요청 설정도 적용되지 않는다. 메시지가 손실될 수 있지만, 서버로부터 ack에 대한 응답을 기다리지 않기 때문에 매우 빠르게 메시지를 보낼 수 있어 높은 처리량을 얻을 수 있다. > acks=1 : 만약 1로 설정하는 경우 리더는 데이터를 기록하지만, 모든 팔로워는 확인하지 않는다. 이 경우 일부 데이터의 손실이 발생할 수도 있다. > acks=all 또는 -1 : 만약 all 또는 -1로 설정하는 경우 리더는 ISR의 팔로워로부터 데이터에 대한 acks를 기다린다. 하나의 팔로워가 있는 한 데이터는 손실되지 않으며, 데이터 무손실에 대해 가장 강력하게 보장한다. |
| buffer.memory | 프로듀서가 카프카 서버로 데이터를 보내기 위해 잠시 대기(배치 전송이나 딜레이 등)할 수 있는 전체 메모리 바이트(bytes)이다. |
| compression.type | 프로듀서가 데이터를 압축해서 보낼 수 있는데, 어떤 타입으로 압축할지를 정할 수 있다. 옵션으로 none, gzip, snappy, lz4 같은 다양한 포맷 중 하나를 선택할 수 있다. |
| retries | 일시적인 오류로 인해 전송에 실패한 데이터를 다시 보내게 된다. |
| batch.size | 프로듀서는 같은 파티션으로 보내는 여러 데이터를 함께 배치로 보내려고 시도한다. 이러한 동작은 클라이언트와 서버 양쪽에 성능적인 측면에서 도움이 된다. 이 설정으로 배치 크기 바이트(batch size byte) 단위를 조정할 수 있다. 정의된 크기보다는 큰 데이터는 배치를 시도하지 않게 된다. 배치를 보내기 전 클라이언트 장애가 발생하면, 배치 내에 있던 메시지는 전달되지 않는다. 만약 고가용성이 필요한 메시지의 경우라면 배치 사이즈를 주지 않는 것도 하나의 방법일 수 있다. |
| linger.ms | 배치형태의 메시지를 보내기 전에 추가적인 메시지들을 기다리는 시간을 조정한다. 카프카 프로듀서는 지정된 배치 사이즈에 도달하면 이 옵션과 관계없이 즉시 메시지를 전송하고, 배치 사이즈에 도달하지 못한 상황에서 linger.ms 제한 시간이 도달했을 때 메시지들을 전송한다. 0이 기본값(지연 없음)이며, 0보다 큰 값을 설정하면 지연 시간은 조금 발생하지만 처리량은 좋아진다. |
| max.request.size | 프로듀서가 보낼 수 있는 최대 메시지 바이트 사이즈이다. 기본값은 1MB이다. |
카프카 컨슈머 주요 옵션 (https://kafka.apache.org/documentation/#consumerconfigs)
| 옵션 | 설명 |
| bootstrap.servers | 카프카 클러스터에 처음 연결을 하기 위한 호스트와 포트 정보로 구성된 리스트 정보를 나타낸다. 정의된 포맷은 "호스트명:포트, 호스트명:포트, 호스트명:포트"이다. 전체 카프카 리스트가 아닌 호스트 하나만 입력해 사용할 수도 있지만 이 방식은 추천하지 않는다. 카프카 클러스터는 살아있는 상태이지만 해당 호스트만 장애가 발생하는 경우에는 접속이 불가하기 때문에, 리스트 전체를 입력하는 방식을 권장한다. |
| fetch.min.bytes | 한번에 가져올 수 있는 최소 데이터 사이즈이다. 만약 지정한 사이즈보다 작은 경우, 요청에 대해 응답하지 않고 데이터가 누적될때까지 기다린다. |
| group.id | 컨슈머가 속한 컨슈머 그룹을 식별하는 식별자이다. 그룹 아이디는 매우 중요한 설정이다. |
| enable.auto.commit | 백그라운드로 주기적으로 오프셋을 커밋한다. |
| auto.offset.reset | 카프카에서 초기 오프셋이 없거나 현재 오프셋이 더이상 존재하지 않은 경우(데이터가 삭제)에 다음 옵션으로 리셋한다. - earliest : 가장 초기의 오프셋값으로 설정한다. - lastest : 가장 마지막의 오프셋값으로 설정한다. - none : 이전 오프셋값을 찾지 못하면 에러를 나타낸다. |
| fetch.max.bytes | 한번에 가져올 수 있는 최대 데이터 사이즈 |
| request.timeout.ms | 요청에 대해 응답을 기다리는 최대 시간 |
| session.timeout.ms | 컨슈머와 브로커 사이의 세션 타임 아웃 시간. 브로커가 컨슈머가 살아있는 것으로 판단하는 시간(기본값 10초) 만약 컨슈머가 그룹 코디네이터에게 하트비트를 보내지 않고 session.timeout.ms이 지나면 해당 컨슈머는 종료되거나 장애가 발생한 것으로 판단하고 컨슈머 그룹은 rebalance를 시도합니다. session.timeout.ms은 하트비트 없이 얼마나 오랫동안 컨슈머가 있을 수 있는지를 제어하며, 이 속성은 heartbeat.interval.ms와 밀접한 관련이 있다. 일반적인 경우 두 속성이 함께 수정된다. session.timeout.ms를 기본값보다 낮게 설정하면 실패를 빨리 감지할 수 있지만, 가비지 컬렉션이나 poll 루프를 완료하는 시간이 길어지게 되면 원하지 않게 리밸런스가 일어나기도 한다. 반대로 session.timeout.ms를 높게 설정하면 원하지 않는 리밸런스가 일어날 가능성은 줄지만 실제 오류를 감지하는데 시간이 오래걸릴 수 있다. |
| heartbeat.interval.ms | 그룹 코디네이터에게 얼마나 자주 KafkaConsumer poll() 메소드로 하트비트를 보낼 것인지 조정한다. session.timeout.ms와 밀접한 관계가 있으며 session.timeout.ms보다 낮아야 한다. 일반적으로 3분의 1 정도로 설정한다. (기본값은 3초) |
| max.poll.records | 단일 호출 poll()에 대한 최대 레코드 수를 조정한다. 이 옵션을 통해 애플리케이션이 폴링 루프에서 데이터 양을 조정할 수 있다. |
| max.poll.interval.ms | 컨슈머가 살아있는지를 체크하기 위해 하트비트를 주기적으로 보내는데, 컨슈머가 계속해서 하트비트만 보내고 실제로 메시지를 가져가지 않는 경우가 있을 수도 있다. 이러한 경우 컨슈머가 무한정 해당 파티션을 점유할 수 없도록 주기적으로 poll을 호출하지 않으면 장애라고 판단하고 컨슈머 그룹에서 제외한 후 다른 컨슈머가 해당 파티션에서 메시지를 가져갈 수 있게 한다. |
| auto.commit.interval.ms | 주기적으로 오프셋을 커밋하는 시간 |
| fetch.max.wait.ms | fetch.min.bytes에 의해 설정된 데이터보다 적은 경우 요청에 응답을 기다리는 최대 시간 |
카프카 프로듀서
카프카에서는 메시지를 생산(produce)해서 카프카의 토픽으로 메시지를 보내는 역할을 하는 애플리케이션, 서버 등을 모두 프로듀서라고 부른다. 프로듀서의 주요 기능은 각각의 메시지를 토픽 파티션에 매핑하고 파티션의 리더에 요청을 보내는 것이다.
키 값을 정해 해당 키를 가진 모든 메시지를 동일한 파티션으로 전송할 수 있다. 만약 키 값을 입력하지 않으면, 파티션은 라운드 로빈 방식으로 파티션에 균등하게 분배된다.
프로듀서를 이용해 카프카로 메시지를 보내려면 토픽이 있어야 하므로 미리 토픽을 생성한다. 카프카의 옵션 중에 auto.create.topics.enable = true로 되어있는 경우에는 프로듀서가 카프카에 존재한지 않는 토픽으로 메시지를 보내면, 자동으로 토픽이 생성된다.
카프카에서는 테스트 목적 등으로 토픽에 메시지를 보낼 수 있는 명령어를 제공한다. 명령어의 위치는 카프카 설치 경로 하위 bin 디렉토리이고 명령어는 kafka-console-producer.sh 이다. 추가 옵션이 있는데, --broker-list 옵션으로 "브로커의 호스트명:포트번호, 호스트명:포트번호" 형식으로 카프카 클러스터 내 모든 브로커 리스트를 입력한다. --topic 옵션으로 메시지를 보내고자 하는 토픽 이름을 명시한다.
카프카는 스칼라를 기반으로, 메인 클라이언트 라이브러리는 자바로 만들어진 애플리케이션이다. 실제 운영황경에서는 프로듀서의 send() 부분을 완벽하게 이해한 후 코드가 작성되어야 한다. 프로듀서에서 send()로 메시지를 보내는 방식은 3가지이다.
1) 메시지를 보내고 확인하지 않기
프로듀서에서 서버로 메시지를 보내고 난 후에 성공적으로 도착했는지까지 확인하지는 않는다. 카프카는 항상 살아있는 상태이고 프로듀서가 자동으로 재전송하기 때문에 대부분의 경우 성공적으로 전송되지만, 일부 메시지는 손실될 수도 있다.
Producer<String, String> producer = new KafkaProducer<String, String>(props);
try {
/*
* send() 메소드를 사용해 ProducerRecord를 보낸다.
* 메시지는 버퍼에 저장되고 별도의 스레드를 통해 브로커로 전송한다.
*
* send()는 자바 Future 객체로 RecordMetadata를 리턴받지만,
* 리턴값을 무시하기 때문에 메시지가 성공적으로 전송되었는지 알 수 없다.
*
* 이 방식은 메시지 손실 가능성이 있기 때문에 일반적인 서비스 환경에서는 사용하지 않는다.
*/
producer.send(new ProducerRecord<String, String>("peter-topic", "Apache Kafka is a distributed streaming platform"));
} catch (Exception exception) {
// 카프카 브로커에게 메시지를 보낸 후의 에러는 무시하지만, 보내기 전에 에러가 발생하면 예외처리 가능
exception.printStackTrace();
} finally {
producer.close();
}
2) 동기 전송
프로듀서는 메시지를 보내고 send() 메소드의 Future 객체를 리턴한다. get() 메소드를 사용해 Future를 기다린 후 send()가 성공했는지 실패했는지 확인한다. 이러한 방법을 통해 메시지마다 브로커에게 전송한 메시지가 성공했는지 실패했는지 확인하여 더욱 신뢰성 있는 메시지 전송을 할 수 있다.
Producer<String, String> producer = new KafkaProducer<String, String>(props);
try {
/*
* get() 메소드를 이용해 카프카의 응답을 기다린다. 메시지가 성공적으로 전송되지 않으면 예외가 발생하고,
* 에러가 없다면, 메시지가 기록된 오프셋을 알 수 있는 RecordMetadata를 얻게 된다.
* RecordMetadata를 이용해 파티션과 오프셋 정보를 출력한다.
*/
RecordMetadata metadata = producer.send(
new ProducerRecord<String, String>("peter-topic", "Apache Kafka is a distributed streaming platform")
).get();
System.out.printf("Partition: %d, Offset: %d", metadata.partition(), metadata.offset());
} catch (Exception exception) {
/*
* 카프카로 메시지를 보내기 전과 보내는 동안 에러가 나는 경우 예외가 발생한다.
* 예외는 크게 두 가지로 구분되는데, 재시도가 가능한 예외가 재시도가 불가능한 예외가 있다.
* 재시도가 가능한 에러는 다시 전송하여 해결할 수 있다.
*
* 예를 들면, 커넥션 에러 등은 재연결되면서 해결되기도 한다.
* 재시도가 불가능한 예외는 메시지가 너무 큰 경우 등이 있다.
*/
exception.printStackTrace();
} finally {
producer.close();
}
3) 비동기 전송
프로듀서는 send() 메소드를 콜백과 같이 호출하고 카프카 브로커에서 응답을 받으면 콜백한다. 만약 프로듀서가 보낸 모든 메시지에 대해 응답을 기다린다면 응답을 기다리는 시간이 더 많이 소요된다. 하지만 비동기적으로 전송한다면 응답을 기다리지 않기 때문에 더욱 빠른 전송이 가능하다. 또한 메시지를 보내지 못했을때 예외를 처리하게 해 에러를 기록하거나 향후 분석을 위해 에러 로그 등에 기록할 수 있다.
// 콜백을 사용하기 위해 org.apache.kafka.clients.producer.Callback를 구현하는 클래스가 필요하다.
class PeterCallback implements Callback {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (metadata != null) {
System.out.println("Partition : " + metadata.partition()
+ ", Offset :" + metadata.offset() + "");
} else {
// 카프카가 오류를 리턴하면, onCompletion()는 예외를 갖게 된다.
// 실제 운영환경에서는 추가적인 예외처리가 필요하다.
exception.printStackTrace();
}
}
}
Producer<String, String> producer = new KafkaProducer<String, String>(props);
try {
producer.send(new ProducerRecord<String, String>("peter-topic", "Apache Kafka is a distributed streaming platform")
, new PeterCallback()); // 프로듀서에서 레코드를 보낼때 콜백 오브젝트를 같이 보낸다.
} catch(Exception exception) {
exception.printStackTrace();
} finally {
producer.close();
}전송 방식에 따라 메시지를 보내는 속도 차이가 발생할 수 있다. 운영 중인 환경에 알맞게 동기, 비동기 방식을 선택해 사용하는 것을 추천한다.
프로듀서의 경우 key 옵션을 줄 수 있는데, 해당 옵션을 주지 않을 경우 라운드로빈 방식으로 파티션마다 균등하게 메시지를 보내게 되고, key를 지정하여 특정 파티션으로만 메시지를 보낼 수 있다.
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class KafkaBookProducerKey {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "...");
props.put("acks", "1");
props.put("compression.type", "gzip");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
String testTopic = "peter-topic2";
String oddKey = "1";
String eventKey = "2";
for (int i = 1; i < 11; i++) {
if (i % 2 == 1) {
producer.send(new ProducerRecord<String, String>(testTopic, oddkey,
String.format("%d - Apache Kafka is a distributed streaming platform - key=" + oddKey, i)));
} else {
producer.send(new ProducerRecord<String, String>(testTopic, oddkey,
String.format("%d - Apache Kafka is a distributed streaming platform - key=" + evenKey, i)));
}
}
producer.close();
}
}위와 같이 프로듀서에서는 메시지를 보낼때 key값을 지정해 해당 key로 지정된 메시지는 특정 파티션으로만 보낼 수있는 기능을 제공하고 있다.
프로듀서 메시지 전송 방법
프로듀서의 옵션 중 acks 옵션을 어떻게 설정하는지에 따라 카프카로 메시지를 전송할때 메시지 손실 여부와 메시지 전송 속도 및 처리량등이 달라지게 된다. 각 옵션은 정확하게 이해하게 사용해야 한다.
1) 메시지 손실 가능성이 높지만 빠른 전송이 필요한 경우
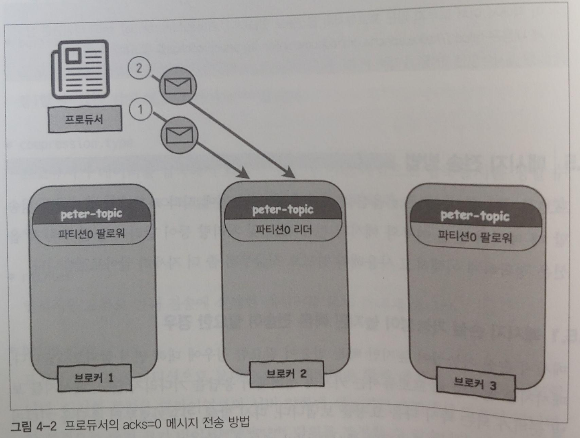
메시지를 전송할 때 프로듀서는 카프카 서버에서 응답을 기다리지 않고, 메시지를 보낼 준비가 되는 즉시 다음 요청을 보내게 된다. 카프카로부터 응답을 기다리지 않고 프로듀서만 준비되면 즉시 보내기 때문에 매우 빠르게 메시지를 보낼 수 있다. 하지만 이런방법으로 사용하게 되면, 프로듀서가 카프카로부터 자신이 보낸 메시지에 대해 응답을 기다리지 않기 때문에 메시지가 손실될 수 있다.
일부 메시지 손실을 감안하더라도 매우 빠르게 전송이 필요한 경우에 사용하는 옵션은 acks=0으로 설정하면 된다. 메시지 손실이 발생한다고 해서 프로듀서가 보내는 메시지의 90% 이상 손실된다는 의미는 아니다. 일반적인 운영환경의 경우 메시지 손실 없이 빠르게 보내지만, 브로커가 다운되는 장애 등의 경우에 메시지 손실 가능성이 높은 상태에 놓이게 된다.
2) 메시지 손실 가능성이 적고, 적당한 속도의 전송이 필요한 경우
이 옵션(acks=1)은 프로듀서가 카프카로 메시지를 보낸 후 보낸 메시지에 대해 카프카가 잘 받았는지 확인(acks)을 한다. 응답 대기 시간 없이 계속 메시지만 보내던 방법과 달리 확인을 기다리는 시간이 추가되어 메시지를 보내는 속도는 약간 떨어지게 된다.
acks=1은 메시지 하나를 보내기 위해 '보내는 행동 + 응답을 받는 행동'을 하여메시지를 하나 보내는데 추가적인 시간이 필요하게 된다. 보낸 메시지에 대한 응답을 받기 때문에 acks=0과 비교해 메시지 손실률은 매우 낮다. acks=1의 경우, 보낸 메시지에 대해 응답을 받기 때문에 메시지 손실이 없을것 같지만, 아주 예외적인 상황으로 acks=1의 경우에도 메시지 일부가 손실되는 현상이 발생하게 된다.
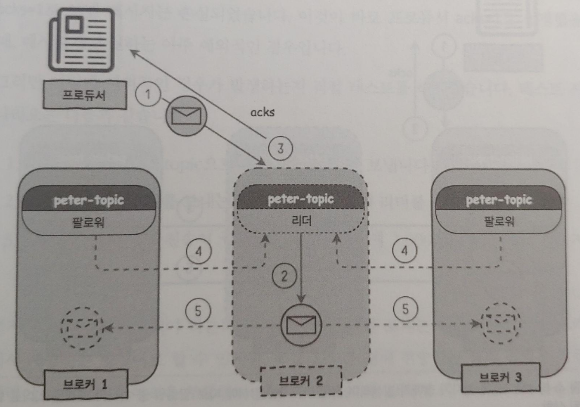
메시지 손실 등의 문제가 발생하는 경우는 리더에 장애가 발생하는 순간이다. 그러나 리더에 장애가 발생한다고 해서 100%의 확률로 메시지가 손실되는 것은 아니고 특별한 상황이 발생했을 때만 메시지 일부가 손실된다. 파티션 리더가 급작스럽게 다운된다면, 해당 메시지를 가져오지 못한 팔로워들은 해당 메시지를 가지고 있지 않게 된다. 카프카에서는 리플리케이션 동작 방식에 따라 리더가 다운되었기 때문에 팔로워 중 하나가 새로운 리더가 되고, 프로듀서의 요청을 처리하게 된다.
프로듀서 입장에서 보면 acks=1 옵션의 규칙에 따라 메시지를 전송하고 보낸 메시지에 대해 리더로부터 acks를 받았기 때문에 카프카에 잘 저장된 것으로 인지하고, 다음 메시지를 전송할 준비를 한다. 프로듀서 역시 오류 등은 없었으며 모두 미리 정의된 프로세스에 따라 처리했다. 즉 프로듀서, 리더, 팔로워 어느 누구도 잘못된 동작을 하지 않았지만, 이렇게 프로듀서가 acks=1로 보낸 메시지는 손실되었다.
최근 프로듀서 애플리케이션으로 많이 사용하는 Logstash, Filebeat 등에서는 프로듀서의 acks 옵션 기본값을 1로 하고 있고, 다른 프로듀서 애플리케이션들도 acks 옵션의 기본값이 1인 경우가 많이 있다. 특별한 경우가 아니라면 속도와 안전성을 확보할 수 있는 acks=1로 사용하는 방법을 추천한다.
3) 전송 속도는 느리지만 메시지 손실이 없어야 하는 경우
프로듀서의 acks=1의 경우에도 아주 예외적인 경우로 일부 메시지가 손실되는 상황이 발생하게 된다. 카프카를 사용하는 사용자의 입장에서 절대 손실되지 않는 메시지를 보내는 경우도 있다. 그래서 카프카에서는 acks=1보다 더 강력한 보장을 할 수 있는 acks=all이라는 옵션을 제공했다. akcs=all의 동작 방법은 프로듀서가 메시지를 전송하고 난 후 리더가 메시지를 받았는지 확인하고 추가로 팔로워까지 메시지를 받았는지 확인하는 것이다.
속도적인 측면으로 볼때, acks 옵션 중에 가장 느리지만 메시지 손실을 허용하지 않을 경우 사용하는 옵션이다. acks=all을 완벽하게 사용하고자 한다면, 프로듀서의 설정 뿐만 아니라 브로커의 설정도 같이 조정해야 한다. 브로커의 설정에 따라 응답 확인을 기다리는 수가 달라지게 된다.
3-1) 프로듀서의 acks=all과 브로커의 min.insyc.replicas=1
메시지 손실을 허용하지 않도록 프로듀서의 acks 설정은 all로 지정한다. 브로커의 환경설정 파일인 server.properties에서 설정을 변경할 수 있다. 최소 리플리케이션 팩터를 지정하는 옵션은 min.insync.replicas이다.

(1) 프로듀서가 acks=all 옵션으로 peter-topic의 리더에게 메시지를 보낸다.
(2) peter-topic의 리더는 메시지를 받은 후 저장한다.
(3) peter-topic의 리더는 min.insync.replicas가 1로 설정되어 있고 최소 하나의 리플리케이션 조건을 갖췄기 때문에 프로듀서에게 메시지를 받았다고 acks를 보낸다.
손실없는 메시지 전송을 위해 프로듀서가 acks=all 옵션으로 메시지를 전송했지만, acks=1과 동일하게 동작하게 된다. 이렇게 동작하는 이유는 바로 브로커 환경설정에 min.insync.replicas에 정의된 값이 1이기 때문이다. 카프카에서는 프로듀서만 acks=all로 메시지를 보낸다고 해서 손실 없는 메시지를 보장해주는 것이 아니기 때문에 옵션을 잘 이해하고 설정해야 한다.
3-2) 프로듀서의 acks=all과 브로커의 min.insync.replicas=2
브로커 환경설정에서 min.insync.replicas의 옵션이 2로 되어있다.
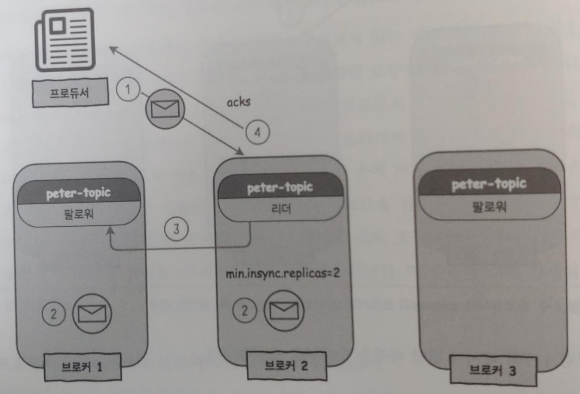
(1) 프로듀서가 acks=all 옵션으로 peter-topic의 리더에게 메시지를 보낸다.
(2) peter-topic의 리더는 메시지를 받은 후 저장한다. 브로커1에 있는 팔로워는 변경된 사항이나 새로 받은 메시지가 없는지를 리더로부터 주기적으로 확인하면서, 새로운 메시지가 전송된 것을 확인하면 자신도 리더로부터 메시지를 가져와 저장한다.
(3) peter-topic의 리더는 min.insync.replicas가 2로 설정되어 있기 때문에 acks를 보내기 전 최소 2개의 리플리케이션을 유지하는지 확인한다.
(4) peter-topic의 리더는 프로듀서가 전송한 메시지에 대해 acks를 프로듀서에게 보낸다.
아파치 카프카 문서에서는 손실 없는 메시지 전송을 위한 조건으로 프로듀서는 acks=all, 브로커의 min.insync.replicas의 옵션은 2, 토픽의 리플리케이션 팩터는 3으로 권장하고 있다. 브로커1이 다운되는 현상이 발생하더라도 남아있는 팔로워가 또 있기 때문에 min.insync.replicas=2를 유지할 수 있게 된다. 즉, 1대 정도의 서버 장애가 발생하더라도 손실없는 메시지 전송을 유지할 수 있다.
손실없는 메시지 전송을 원한다면, acks=all과 min.insync.replicas=2와 리플리케이션 팩터=3의 조건으로 사용하면 된다.
3-3) 프로듀서의 acks=all과 브로커의 min.insync.replicas=3
손실없는 메시지 전송을 위해 min.insync.replicas=3으로 설정해야 하는 것이 아닌가라고 생각할 수 있다. 왜 min.insync.replicas=2로 설정해야 하는지 그 이유를 한번 알아보자. 브로커 환경설정에서 min.insync.replicas의 옵션이 3으로 되어있다고 가정해본다.

(1) 프로듀서가 acks=all 옵션으로 peter-topic의 리더에게 메시지를 보낸다.
(2) peter-topic의 리더는 메시지를 받은후 저장한다. 브로커1에 있는 팔로워는 변경된 사항이나 새로 받은 메시지가 없는지를 리더로부터 주기적으로 확인하면서, 새로운 메시지가 전송된것을 확인하면 자신도 리더로부터 메시지를 가져와 저장한다.
(3) peter-topic의 리더는 min.insync.replicas가 3으로 설정되어 있기 때문에 akcs를 보내기 전 최소 3개의 복제를 유지하는지 확인한다.
(4) peter-topic의 리더는 프로듀서가 전송한 메시지에 대해 akcs를 프로듀서에게 보낸다.
동작 방법을 이해하니 min.insync.replicas=3이 가장 강력한 방법이라는 생각이 든다. 왜 카프카에서는 손실없는 메시지 전송을 위해 min.insync.replicas=3이 아닌 min.insync.replicas=2를 추천할까? 일허게 설정한 경우 프로듀서가 토픽의 리더에게 메시지를 전송하게 되면, 리더 + 팔로워 + 팔로워 이렇게 3곳에서 모두 메시지를 받아야만 리더는 프로듀서에게 메시지를 잘받았다는 확인(acks)를 보낼 수 있다.
하지만, 여기에서 브로커 3번을 갖에로 종료하게 된다면, 팔로워 하나가 다운되면서 ISR에는 리더와 팔로워 하나만 남아있게 된다. 결국 옵션으로 설정한 조건을 충족시킬 수 없는 상황이 발생했기 때문에 로그에 에러가 발생하게 된다. 카프카는 브로커 하나가 다운되더라도 크리티컬한 장애 상황없이 서비스를 잘 처리할 수 있도록 구성되어 있는데, 만약 acks=all + min.insync.replicas=3으로 설정하게 되면 브로커 하나만 다운되더라도 카프카로 메시지를 보낼 수 없는 클러스터 전체 장애와 비슷한 상황이 발생하게 된다. 이러한 이유로 카프카에서는 손실없는 메시지 전송을 위해 프로듀서의 acks=all로 사용하는 경우 브로커의 min.insync.replicas=2로 설정하고, 토픽의 리플리케이션 팩터는 3으로 설정하기를 권장하고 있다. 물론 아주 예외적인 상황으로 브로커가 2대가지 다운되는 경우에는 프로듀서들의 요청을 처리할 수 없는 상황이 발생한다.
카프카 컨슈머
프로듀서가 메시지를 생산해서 카프카의 토픽으로 메시지를 보내면 그 토픽의 메시지를 가져와서 소비하는 역할을 하는 애플리케이션, 서버 등을 지칭하여 컨슈머라고 한다.
컨슈머의 주요 기능은 특정 파티션을 관리하고 있는 파티션 리더에게 메시지 가져오기 요청을 하는 것이다. 각 요청은 로그의 오프셋을 명시하고 그 위치로부터 로그 메시지를 수신한다. 그래서 컨슈머는 가져올 메시지의 위치를 조정할 수 있고, 필요하다면 이미 가져온 데이터도 다시 가져올 수 있다. 이렇게 이미 가져온 메시지를 다시 가져올 수 있는 기능은 RabbitMQ와 같은 일반적인 메시지큐 솔루션에서는 제공하지 않는 기능이다. 최근에는 메시지큐 솔루션 사용자들에게 이러한 기능이 필수 기능으로 자리잡고 있다.
카프카에서 컨슈머라고 불리우는 컨슈머는 두가지 종류가 있는데 하나는 '올드 컨슈머'라고 부르고, 다른 하나는 '뉴 컨슈머'라고 한다. 두 컨슈머의 가장 큰 차이는 주키퍼의 사용 유무이다. 구버전의 카프카에서는 컨슈머의 오프셋을 주키퍼의 지노드에 저장하는 방식을 지원하다가 최신 버전 카프카는 컨슈머의 오프셋 저장을 주키퍼가 아닌 카프카의 토픽에 저장하는 방식으로 변경했다.
컨슈머를 실행할 때는 항상 컨슈머 그룹이라는 것이 필요하다. 컨슈머가 메시지를 가져올때, 컨슈머 그룹을 따로 지정하지 않으면 임의로 컨슈머 그룹이 생성되게 된다.
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class KafkaBookConsumer1 {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "...");
props.put("group.id", "peter-consumer"); // 컨슈머에서 사용할 그룹 아이디
props.put("enable.auto.commit", "true");
/*
* 오프셋 리셋 값을 지정한다. earliest와 latest 두가지 옵션이 있는데,
* earliest는 토픽의 처음부터 메시지를 가져오고, latest는 토픽의 가장 마지막부터 메시지를 가져온다.
* 기본값은 latest이며, 해당 값으로 가장 많이 사용하지만, 필요한 경우에는 earliest로 변경해 사용할 수 있다.
*/
props.put("auto.offset.reset", "latest");
// 메시지와 키와 값에 문자열을 사용하면 내장된 StringDeserializer를 지정하면 된다.
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializaer");
// subscribe() 메소드를 이용해 메시지를 가져올 토픽을 구독하고, 리스트 형태로 여러개의 토픽을 입력할 수도 있다.
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscirbe(Arrays.asList("peter-topic"));
try {
// 무한 루프이다. 메시지를 가져오기 위해 카프카에 지속적으로 poll()을 하게 된다.
while (true) {
/*
* 컨슈머는 카프카에 폴링하는 것을 계속 유지해야 한다. 그렇지 않으면 종료된 것으로 간주되어,
* 컨슈머에 할당된 파티션은 다른 컨슈머에 전달되고 새로운 컨슈머에 의해 컨슘된다.
* poll()은 타임아웃 주기이고, 데이터가 컨슈머 버퍼에 없다면 poll()은 얼마나 오랫동안 블럭할지를 조정한다.
* 만약 0으로 설정하면 poll()은 즉시 리턴하게 되고, 값을 입력하면 정해진 시간동안 대기하게 된다.
*/
ConsumerRecords<String, String> records = consumer.poll(100);
/*
* poll()은 레코드 전체를 리턴하고, 레코드에는 토픽, 파티션, 파티션의 오프셋, 키 값을 포함하고 있다.
* 한번에 하나의 메시지만 가져오는 것이 아니기 때문에 N개의 메시지 처리를 위해 반복문이 필요하다.
* 실제 운영환경에서는 하둡에 저장하거나 데이터베이스에 저장하거나 수신한 메시지를 이용해
* 특정 레코드를 분석하는 로직 등을 추가할 수 있다.
*/
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Topic: %s, Partition: %s, Offset: %d, Key: %s, Value: %s\n",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
}
} finally {
/*
* 컨슈머를 종료하기 전에 close() 메소드를 사용한다. 이렇게 하면 네트워크 연결과 소켓을 종료한다.
* 컨슈머가 하트비트를 보내지 않아 그룹 코디네이터가 해당 컨슈머가 종료된 것을 감지하는 것보다 빠르게 감지되고
* 즉시 리밸런스가 일어난다.
*/
consumer.close();
}
}
}파티션과 메시지 순서
1) 파티션 3개로 구성한 peter-01 토픽과 메시지 순서
프로듀서가 peter-01 토픽으로 메시지를 a, b, c, d, e 순으로 보냈지만 해당 메시지들은 하나의 파티션에만 순서대로 저장되는 것이 아니라 각각의 파티션별로 메시지가 저장되게 된다. 그리고 컨슈머가 peter-01 토픽에서 메시지를 가져올 때, 컨슈머는 프로듀서가 어떤 순서대로 메시지를 보냈는지는 알 수 없다. 컨슈머는 오직 파티션의 오프셋 기준으로만 메시지를 가져온다.
이렇게 카프카에서는 토픽의 파티션이 여러개인 경우, 메시지의 순서는 보장할 수없다. 카프카 컨슈머의 메시지 처리 순서는 다음과 같은 방식으로 처리된다. 카프카 컨슈머에서의 메시지 순서는 동일한 파티션 내에서는 프로듀서가 생성한 순서와 동일하게 처리하지만, 파티션과 파티션 사이에서는 순서를 보장하지 않는다.
하지만 카프카를 사용하는 사용자에 따라 메시지의 순서를 반드시 보장해야 하는 경우도 있다. 이런 경우에는 다음 방법을 이용한다.
2) 파티션 1개로 구성한 peter-02 토픽과 메시지 순서
카프카의 토픽으로 메시지를 보내고 받을때 메시지의 순서를 정확하게 보장받기 위해서는 토픽의 파티션 수를 1로 지정해 사용해야 한다. 메시지들이 어떻게 들어가 있는지 확인해보면 다음과 같다.

프로듀서가 보낸 메시지 순서대로 메시지들은 파티션 0번에 순서대로 저장되어 있고, 메시지 순서에 맞추어 파티션 0번의 오프셋도 순차적으로 증가하게 된다. 컨슈머는 파티션의 오프셋 기준으로만 메시지를 가져오기 때문에 프로듀서가 보낸 메시지 순서와 동일하게 메시지를 가져올 수 있는 것이다.
카프카를 상요하면서 메시지의 순서를 보장해야 하는 경우에는 토픽의 파티션 수를 1로 설정하면 된다. 메시지의 순서는 보장되지만 파티션 수가 하나이기 때문에 분산해서 처리할 수 없고 하나의 컨슈머에서만 처리할 수 있기 때문에 처리량이 높지 않다. 즉 처리량이 높은 카프카를 사용하지만 메시지 순서를 보장해야 한다면 파티션 수를 하나로 만든 토픽을 사용해야 하며, 어느정도 처리량이 떨어지는 부분은 감안해야 한다.
컨슈머 그룹
일반적으로 컨슈머는 카프카 토픽에서 메시지를 읽어오는 역할을 한다. 컨슈머 그룹은 하나의 토픽에 여러 컨슈머 그룹이 동시에 접속해 메시지를 가져올 수 있다. 기존의 다른 메시징큐 솔루션에서 컨슈머가 메시지를 가져가면 큐에서 삭제되어 다른 컨슈머가 가져갈 수 없는 것과는 다른 방식인데 이방식이 좋은 이유는 최근에 하나의 데이터를 다양한 용도로 사용하는 요구가 많아졌기 때문이다.
컨슈머 그룹은 컨슈머를 확장시킬 수도 있다. 만약 프로듀서가 토픽에 보내는 메시지 속도가 갑자기 증가해 컨슈머가 메시지를 가져가는 속도보다 빨라지면, 컨슈머가 처리하지 못한 메시지들이 점점 많아지게 되어, 카프카로 메시지가 들어오는 시간과 그 메시지가 컨슈머에 의해 카프카에서 나가는 시간의 차이는 점점 벌어지게 된다. 이런 경우, 컨슈머가 메시지를 정해진 시간 내에 모두 처리할 수 없기 때문에 컨슈머를 확장해야 한다. 단순하게 컨슈머만 확장한다면, 기존의 컨슈머의 오프셋 정보와 새로 추가된 컨슈머의 오프셋 정보가 뒤섞여 메시지들이 뒤죽박죽될 것이다. 그래서 카프카에서는 동일한 토픽에 대해 여러 컨슈머가 메시지를 가져갈 수 있도록 컨슈머 그룹이라는 기능을 제공한다. 이러한 기능을 통해 컨슈머는 확장이 용이해지고, 컨슈머의 장에도 빠른 대처가 가능하다.
만약 예기치 않게 갑자기 프로튜서가 토픽으로 많은 메시지를 전송하게 된다면, 하나의 컨슈머만 있을때 컨슈머가 메시지를 가져가는 속도보다 프로듀서가 메시지를 보내는 속도가 더 빠르게 되어, 시간이 지남에 따라 컨슈머가 아직 읽어가지 못한 메시지들이 점점 쌓이게 된다. 이런 문제를 해결하기 위해서는 컨슈머를 충분히 확장해야 하며, 카프카에서는 이와 같은 상황을 쉽게 해결할 수 있도록 컨슈머 그룹이라는 기능을 제공한다.

기본적으로 컨슈머 그룹 안에서 컨슈머들은 메시지를 가져오고 있는 토픽의 파티션에 대해 소유권을 공유한다. 컨슈머 그룹 내 컨슈머의 수가 부족해 프로듀서가 전송하는 메시지를 처리하지 못하는 경우에는 컨슈머를 추가해야하며, 추가 컨슈머를 실행할때 동일한 컨슈머 그룹 아이디를 설정하면 위와 같이 구성된다.
이렇게 소유권이 이동하는 것을 리밸런스라고 한다. 이러한 컨슈머 그룹의 리밸런스를 통해 컨슈머 그룹에는 컨슈머를 쉽고 안전하게 추가할 수 있고 제거할 수 있어서 높은 가용성과 확장성을 확보할수 있다. 이러한 컨슈머 그룹의 리밸런스를 통해 컨슈머 그룹에는 컨슈머를 쉽고 안전하게 추가할 수 있고 제거할 수도 있어 높은 가용성과 확장성을 확보할 수 있다.
하지만, 리밸런스를 하는 동안 일시적으로 컨슈머는 메시지를 가져올 수 없다. 그래서 리밸런스가 발생하면 컨슈머 그룹 전체가 일시적으로 사용할 수 없는 단점이 있다. 컨슈머 그룹 내에서 리밸런스가 일어나면 토픽의 각 파티션마다 하나의 컨슈머가 연결된다. 그리고 리밸런스가 끝나게 되면 컨슈머들은 각자 담당하고 있는 파티션으로부터 메시지를 가져오게 된다.
토픽의 컨슈머에는 하나의 컨슈머만 연결할 수있다. 결국 토픽의 파티션 수만큼 최대 컨슈머 수가 연결할 수 있다. 각각의 파티션에 대해서는 메시지 순서를 보장한다. 그런데 만약 하나의 파티션에 두 개의 컨슈머가 연결된다면 안정적으로 메시지 순서를 보장할 수 없게 될 것이다. 그래서 카프카에서는 하나의 파티션에 하나의 컨슈머만 연결할 수 있다.
토픽의 파티션 수와 동일하게 컨슈머 수를 늘렸는데도 프로듀서가 보내는 메시지의 속도를 따라가지 못한다면, 컨슈머만 추가하는 것이 아니라 토픽의 파티션 수를 늘려주고 컨슈머 수도 같이 늘려줘야 한다.
컨슈머가 컨슈머 그룹 안에서 멤버로 유지하고 할당된 파티션의 소유권을 유지하는 방법은 하트비트를 보내는 것이다. 반대로 생각해보면, 컨슈머가 일정한 주기로 하트비트를 보낸다는 사실은 해당 파티션의 메시지를 잘 처리하고 있다는 것이다. 하트비트는 컨슈머가 poll한 때와 가져간 메시지의 오프셋을 커밋할 때 보내게 된다. 만약 컨슈머가 오랫동안 하트비트를 보내지 않으면 세션은 타임아웃되고 해당 컨슈머가 다운되었다고 판단하여 리밸런스가 시작된다.
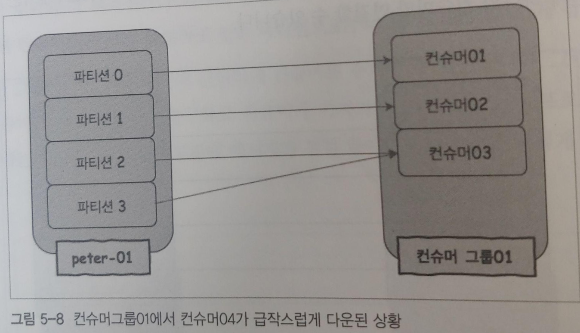
하나의 컨슈머 그룹이 두개의 파티션에서 메시지를 가져오고 있지만, 하나의 파티션에 하나의 컨슈머만 연결되었기 때문에 카프카의 룰을 위반한 것은 아니다. 약간은 불균형한 상황이 발생할 수도 있지만 전체적인 컨슈머 그룹은 안정적으로 동작함으로써 안정성을 확보할 수 있다. 이런 상황을 지속적으로 내버려두면 일부 메시지를 늦게 가져오는 현상이 발생할 수 있기 때문에 모니터링을 통해 컨슈머의 장애 상황을 인지하고, 새로운 컨슈머를 추가해 정상적인 운영상태를 만드는 편이 좋다.
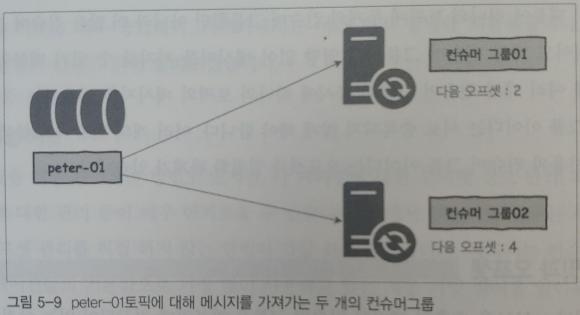
카프카가 다른 메시지 큐 솔루션과 차별화되는 특징은 하나의 토픽(큐)에 대해 여러 용도로 사용할 수 있다는 점이다. 일반적인 메시지 큐 솔루션은 특정 컨슈머가 메시지를 가져가면 큐에서 메시지가 삭제되어 다른 컨슈머는 가져갈 수 없는데 카프카는 컨슈머가 메시지를 가져가도 삭제하지 않는다. 이런 특징을 이용해서 하나의 메시지를 여러 컨슈머가 다른 용도로 사용할 수 있도록 시스템을 구성할 수 있다.
이렇게 여러 컨슈머 그룹들이 하나의 토픽에서 메시지를 가져갈 수 있는 이유는 컨슈머 그룹마다 각자의 오프셋을 별도로 관리하기 때문에 하나의 토픽에 두개의 컨슈머 그룹뿐만 아니라 더 많은 컨슈머 그룹이 연결되어도 다른 컨슈머 그룹에 영향없이 메시지를 가져갈 수 있기 때문이다. 이렇게 여러 개의 컨슈머 그룹이 동시에 하나의 토픽 메시지를 이용하는 경우, 컨슈머 그룹 아이디는 서로 중복되지 않게 해야 한다. 여러개의 컨슈머 그룹에 대한 동시 사용과 컨슈머 그룹 아이디는 오프셋과 밀접한 관계가 있다.
커밋과 오프셋
컨슈머가 poll()을 호출할 때마다 컨슈머 그룹은 카프카에 저장되어 있는 아직 읽지 않은 메시지를 가져온다. 이렇게 동작할 수 있는 것은 컨슈머 그룹이 메시지를 어디까지 가져갔는지를 알 수 있기 때문이다. 컨슈머 그룹의 컨슈머들은 각각의 파티션에 자신이 가져간 메시지의 위치 정보(오프셋)을 기록하고 있다. 각 파티션에 대해 현재 위치를 업데이트하는 동작을 커밋한다고 한다.
카프카는 각 컨슈머 그룹의 파티션별로 오프셋 정보를 저장하기 위한 저장소가 별도로 필요하다. 올드 카프카 컨슈머는 이 오프셋 정보를 주키퍼에 저장했으며 성능 등의 문제로 뉴 컨슈머에서는 카프카 내에 별도로 내부에서 사용하는 토픽(__consumer_offsets)를 만들고 그 토픽에 오프셋 정보를 저장하고 있다. 모든 컨슈머들이 살아있고, 잘 동작하고 있는 동안에는 아무런 영향이 없다. 만약 컨슈머가 갑자기 다운되거나 컨슈머 그룹에 새로운 컨슈머가 조인한다면 컨슈머 그룹 내에서 리밸런스가 일어나게 된다.
리밸런스가 일어난 후 각각의 컨슈머는 이전에 처리했던 토픽의 파티션이 아닌 다른 새로운 파티션에 할당된다. 컨슈머는 새로운 파티션에 대해 가장 최근 커밋된 오프셋을 읽고 그 이후부터 메시지들을 가져오기 시작한다.
만약 커밋된 오프셋이 컨슈머가 실제 마지막으로 처리한 오프셋보다 작으면 마지막 처리된 오프셋과 커밋된 오프셋 사이의 메시지는 중복으로 처리되고, 커밋된 오프셋이 컨슈머가 실제 마지막으로 처리한 오프셋보다 크면 마지막 처리된 오프셋과 커밋된 오프셋 사이의 모든 메시지는 누락된다.
1) 자동 커밋
오프셋을 직접 관리하는 방법도 있지만, 각 파티션에 대한 오프셋 정보 관리, 파티션 변경에 대한 관리 등이 매우 번거로울 수 있다. 그래서 컨슈머를 다루는 사용자가 오프셋 관리를 직접 하지 않는 방법이 가장 쉬운 방법이다. 여기서는 컨슈머 애플리케이션들의 기본값으로 가장 많이 사용하고 있는 자동 커밋 방식을 살펴본다.
자동 커밋을 사용하고 싶을때는 컨슈머 옵션 중 enable.auto.commit=ture로 설정하면 5초마다 컨슈머는 poll()을 호출할 때 가장 마지막 오프셋을 커밋한다. 5초 주기는 기본값이며, auto.commit.interval.ms 옵션을 통해 조정이 가능하다. 컨슈머는 poll을 요청할 때마다 커밋할 시간인지 아닌지 체그하게 되고, poll 요청으로 가져온 마지막 오프셋을 커밋한다.

자동 커밋이 편리한 기능이지만 주의해야할 부분도 있다. 만약 커밋을 해야하는 5초가 되기전인 마지막 커밋 이후 3초가 지나 리밸런스가 일어나면 어떻게 될까?

파티션0번에 대해 마지막 커밋은 4로 되어 있기때문에 컨슈머02는 메시지 5와 6을 가져오게 된다. 하지만 메시지 5와 6은 컨슈머01이 리밸런스 직전에 이미 가져왔던 메시지이다. 결국 메시지 5와 6은 중복으로 처리된다. 만약 중복을 줄이기 위해서 자동 커밋의 시간을 더 줄일 수 있지만, 중복을 완벽하게 제거하는 것은 불가능하다. 이렇게 자동으로 오프셋을 커밋하는 방법은 매우 편리하지만, 중복 등이 발생할 수 있기 때문에 동작에 대해 완벽하게 이해하고 사용하는 것이 중요하다.
2) 수동 커밋
경우에 따라 자동 커밋이 아닌 수동 커밋을 사용해야 하는 경우도 있는데, 이러한 경우는 메시지 처리가 완료될때까지 메시지를 가져온 것으로 간주되어서는 안되는 경웨 사용한다.
컨슈머가 메시지를 가져와서 데이터베이스에 메시지를 저장한다고 가정하겠다. 만약 자동 커밋을 사용하는 경우라면 자동 커밋의 주기로 인해 poll하면서 마지막 값의 오프셋으로 자동 커밋이 되었고, 일부 메시지들은 데이터베이스에는 저장하지 못한 상태로 컨슈머 장애가 발생한다면 해당 메시지들은 손실될 수도 있다. 이러한 경우를 방지하기 위해 컨슈머가 메시지를 가져오자마자 커밋을 하는 것이 아니라, 데이터베이스에 메시지를 저장한 후 커밋을 해야만 안전하게 메세지를 저장할 수 있다.
public class KafkaBookConsumerM0 {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "...");
props.put("group.id", "peter-manual");
// 커밋을 수동으로 해야 하기 때문에 enable.auto.commit를 false로 지정한다.
props.put("enable.auto.commit", "false");
props.put("auto.offset.reset", "latest");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("peter-topic"));
try {
while (true) {
// poll을 호출해 peter-topic으로부터 메시지를 가져온다.
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
{
System.out.printf("Topic: %s, Partition: %s, Offset: %d, Key: %s,
Value: %s\n", record.topic(), record.partition(), record.offset(),
record.key(), record.value());
}
try {
// 메시지를 모두 가져온 후 commitSync를 호출해 커밋한다.
consumer.commitSync();
} catch (CommitFailedException exception) {
e.printStackTrace();
}
}
} finally {
consumer.close();
}
}
}이처럼 수동 커밋은 메시지를 가져온 것으로 간주되는 시점을 자유롭게 조정할 수 있는 장점이 있다. 하지만 수동 커밋의 경우에도 중복이 발생할 수 있다. 메시지들은 데이터베이스에 저장하는 도중에 실패하게 된다면, 마지막 커밋된 오프셋부터 메시지를 다시 가져오기 때문에 일부 메시지들은 데이터베이스에 중복으로 저장될 수 있다. 이렇게 카프카에서 메시지는 한번씩 전달되지만 장애등의 이유로 중복이 발생할 수 있기 때문에 카프카는 적어도 "중복은 있지만 손실은 없다"라는 내용을 보장하게 된다.
3) 특정 파티션 할당
일부의 경우에는 특정한 파티션에 대해 세밀하게 제어하기를 원할 수도 있다.
(1) 키-값의 형태로 파티션에 저장되어 있고, 특정 파티션에 대한 메시지들만 가져와야 하는 경우
(2) 컨슈머 프로세스가 가용성이 높은 구성인 경우, 카프카가 컨슈머의 실패를 감지하고 재조정할 필요없고 자동으로 컨슈머 프로세스가 다른 시스템에 재시작되는 경우.
수동으로 파티션을 할당해 메시지를 가져올 수도 있다. 이러한 방법을 사용하는 경우, 컨슈머 인스턴스마다 컨슈머 그룹 아이디를 서로 다르게 설정해야 한다는 점을 주의해야 한다. 만약 동일한 컨슈머 그룹 아이디를 설정하게 되면, 컨슈머마다 할당된 파티션에 대한 오프셋 정보를 서로 공유하기 때문에 종료된 컨슈머의 파티션을 다른 컨슈머가 할당받아 메시지를 이어서 가져가게 되고 오프셋을 커밋하게 되어, 결국 원치않는 형태로 동작할 수 있다.
4) 특정 오프셋으로부터 메시지 가져오기
카프카의 컨슈머 API를 사용하게 되면 메시지 중복 처리 등의 이유로 경웨 따라 오프셋 관리를 수동으로 하는 경우도 있다. 이러한 경우에는 수동으로 어디부터 메시지를 읽어올지를 지정해야 하는데 이때 seek() 메소드를 사용하면 된다.
'데이터베이스(DA, AA, TA) > 데이터처리' 카테고리의 다른 글
| [Kafka] 아파치 카프카 알아보기(3) - 카프카 소개 (0) | 2019.12.22 |
|---|---|
| [Kafka] 아파치 카프카 알아보기(2) - 운영 가이드 (0) | 2019.12.15 |
| [Kafka] 카프카 파티션의 이해 (0) | 2019.12.14 |
| [ELK] 키바나 사용법 정리 (0) | 2019.06.30 |
| [데이터처리] 로그데이터 다루기(2) - 수집 미들웨어 Fluentd란? (0) | 2019.05.19 |